Нейросеть научили артикуляции Барака Обамы
Синхронизация видео- и аудиодорожек важна во многих областях: политике, бизнесе и искусстве. Так, видеоконференции нередко сопровождаются задержкой сигнала, в результате чего речь изображенного человека не соответствует артикуляции. Искусственная адаптация фонем к микродвижениям, кроме того, актуальна для киноиндустрии: она могла бы упростить озвучивание персонажей. Ранее французские ученые представили алгоритм с обратной функцией - для воспроизведения голоса по положению губ. Системы, способные монтировать аудиоряд в видеоролик, также создаются, однако до сих пор при их разработке использовались только видео, записанные в лабораторных условиях.
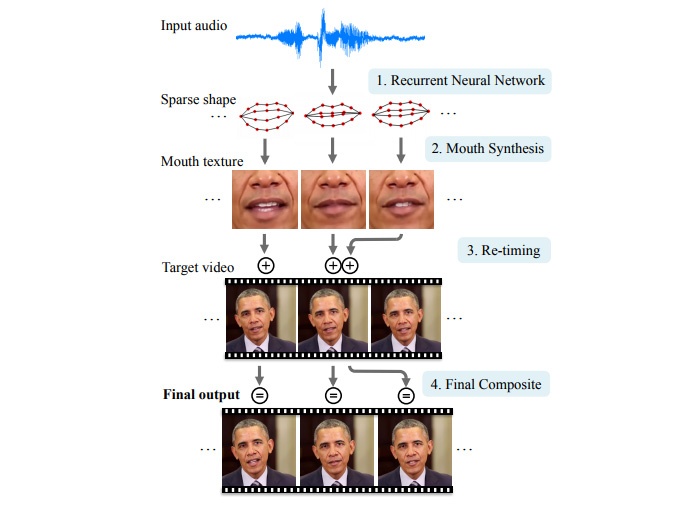
Авторы новой статьи на этапе проектирования алгоритма задействовали записи естественной речи бывшего президента США Барака Обамы. На первом этапе они с помощью рекуррентной нейросети описали артикуляционную мимику политика на основе фонем из четырех его видеообращений к гражданам страны. Затем с помощью полученной модели ученые нарисовали трехмерную маску (с нейтральным выражением) экс-главы государства и обучили систему совмещать изображение с ней и произвольным аудиорядом. Для повышения реалистичности команда также учитывала характерные для бывшего президента движения головы и общую мимику. Тренировка искусственной нейросети продолжалась от 3 трех минут до 14 часов.
Тесты показали, что точность наложения коррелирует с продолжительностью обучения. Так, максимального результата алгоритму удалось достичь после семи и более часов. Авторы отмечают, что последний использовал в качестве базовых единиц сравнительно простые комбинации из не более чем пяти фонем (пентафонов), поскольку вероятность встретить в разных видео более сложные одинаковые последовательности звуков чрезвычайно мала. Эффективность адаптации видеоряда исходя из комбинаций при этом составила от 4,9 процента для пентафонов до 82,9-99,9 процента для три- и дифонов соответственно. Для сравнения, среднее слово в английском языке содержит 3,9 фонемы.
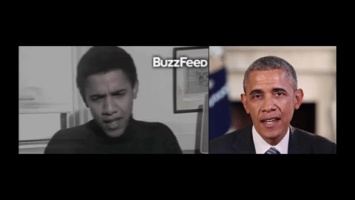
В рамках демонстрации исследователи испытали технологию на четырех других видеозаписях, сделанных во время интервью Обамы актеру Стиву Харви, ток-шоу The View, журналу Harvard Law Review (в 1990 году), а также выступления пародиста. Нейросеть хорошо адаптировала аудиодорожки к видеообращениям. Дополнительно разработку сравнили с аналогичным сервисом Face2face, который весной 2016 года представили специалисты из Стэнфордского университета, Общества Макса Планка и Университета Эрлангена - Нюрнберга. По мнению ученых, новая система позволяет повысить реалистичность целевой записи. При этом, в отличие от Face2face, она может обучаться только по аудиоряду.
Статья опубликована на сайте Вашингтонского университета.
Ранее американский программист создал искусственную нейросеть для превращения мужских лиц на снимках в женские и наоборот.