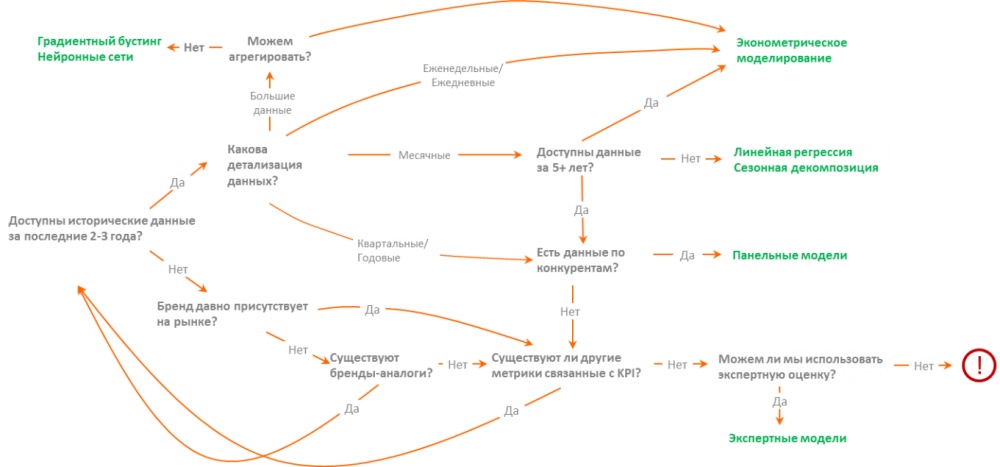
Базовые инструменты прогнозирования ключевых бизнес-показателей

Директор по информационным продуктам и аналитике в рекламном агентстве People & Screens Александр Горбачев написал для vc.ru колонку, в которой рассказал, как корректно строить прогноз бизнес-показателей в зависимости от объема доступных данных: от экспертного мнения и линейного тренда до многофакторного регрессионного анализа и эконометрики.
Задача прогнозирования бизнес-показателей, таких, как продажи или рост знания бренда, всегда была одной из самых актуальных для любого бизнеса. Однако решение этой задачи часто оказывается нетривиальной из-за большого числа факторов, влияющих на результат прогноза, и отсутствия необходимых данных. Выбор оптимальной прогнозной модели будет зависеть от объема доступной информации и постановки задачи.
Представим, что мы запускаем новый продукт в новой категории и хотим получить прогноз развития показателей бизнеса на ближайшие пять лет. Категория новая, как сделать прогноз наиболее реалистичным? Решение такой задачи часто сводится к классическому рецепту приготовления каши из топора. Если в холодильнике пусто, посмотрите, нет ли у вас соли, крупы, масла. Вуаля - каша готова.
Дальше все будет зависеть от специфики продукта и готовности инвестировать в покупку доступа к индустриальным базам данных. Так, например, в фармацевтике существуют базы данных IMS и DSM, которые позволят проанализировать продажи любого лекарственного средства в исторической перспективе с детализацией по регионам, формам выпуска и другими специфическими для этой категории показателями.
В категории FMCG есть аналогичный источник индустриальных данных - Nielsen, в автокатегории - «Автостат» (AEB), в мобильных приложениях - App Annie. У TNS есть панель Marketing Index с мониторингом знания крупных брендов в большинстве категорий. Практически для любого рынка можно подобрать источник данных, позволяющий оценить продажи или близкую к ним метрику.
Если в вашей категории нет никаких источников данных, либо нет возможности получить к ним доступ, имеет смысл прибегнуть к экспертному мнению. Силу экспертного мнения не стоит недооценивать, ведь даже индустриальные источники данных могут ошибаться, а человек с опытом может лучше оценить фактические показатели бизнеса.
Экспертная модель - модель на основе экспертного мнения - это наглядный пример работы нейронной сети, за ней стоит опыт конкретных людей. Принято считать, что точность таких моделей увеличивается с ростом числа опрошенных экспертов.
Так же, как и модели на основе нейронных сетей, экспертные модели можно обучать по мере поступления фактических данных. То есть если вы три квартала подряд спрашивали Васю и Петю о том, какими будут продажи в последующем квартале, и три раза подряд прогноз Пети оказывался точнее, то в четвертый раз прогнозу Пети можно придать больший вес.
Одно из главных преимуществ, и он же главный недостатков экспертных моделей - их простота. Чтобы разработать такую модель, достаточно найти компетентных людей и записать их прогноз. Никаких специальных инструментов не требуется, максимум - калькулятор. Однако такими моделями сложно управлять, и если прогноз не сбудется, то все, что остается - признать, что кто-то из экспертов ошибся.
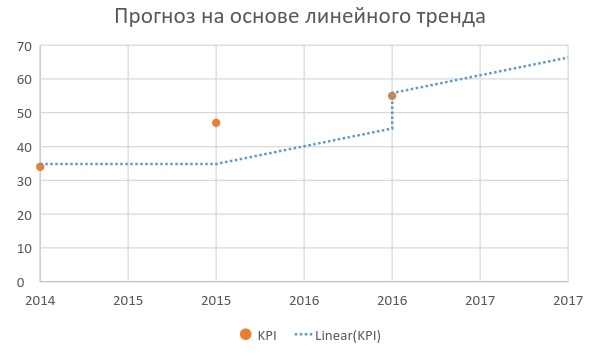
По мере накопления данных стоит постепенно отходить от экспертных моделей в пользу более прозрачных и взвешенных способов прогнозирования. При наличии данных всего за три предыдущих периода уже становится возможным использовать модель линейного тренда.
Почему именно три периода, а не два? Потому что на двух точках погрешность модели всегда будет равна нулю, так как через две точки проходит единственная прямая (в этом случае лучшей моделью будет выбор среднего значения).
В моем опыте был случай, когда производитель шин обратился с просьбой построить прогноз на пять лет вперед на основе замера текущего знания бренда с учетом их рекламного бюджета. Так как замер был только один, мы опирались на экспертную оценку. Через полгода клиент попросил нас уточнить прогноз с учетом новой волны опроса. Но это не могло повлиять на наш прогноз, потому что первый замер производился зимой, а второй летом. А знание марок летних и зимних шин довольно сильно отличается.
Мы объяснили клиенту, что, чтобы построить хотя бы тренд, придется ждать три года. В итоге, чтобы дать более точный прогноз, мы пересекли данные опроса с данными объема поисковых запросов, которые в Wordstat Yandex доступны в детализации по месяцам за последние два года.
В реальности любая модель должна обладать погрешностью, и знание величины этой погрешности не менее ценно, чем сам прогноз. Классическая ошибка при построении прогноза - стремление выбрать такую модель, которая бы полностью описывала исторические данные с нулевой ошибкой, неважно сколько факторов задействовано для описания.
Одним из основных критериев в выборе наиболее подходящей модели прогнозирования должна быть ее способность описывать ранее неизвестные данные при минимальной зависимости от факторов, которые сами требуют предсказания и обладают погрешностью в оценке.
Из двух моделей, одинаково хорошо описывающих исторические данные, лучшей будет та, в которой задействовано меньше факторов.
Самый простой способ построить модель линейного тренда - воспользоваться функцией Trend (тенденция) в Excel. Аналогичные функции есть в любом специализированном ПО для анализа данных. К плюсам такого способа прогнозирования можно отнести его простоту и наглядность. К минусам - не самую высокую точность прогнозирования (бизнес редко живет по линейным законам) и отсутствие возможности управлять прогнозом в зависимости от внешних факторов. Такой способ прогнозирования хорошо подходит для описания ситуаций типа «что, если в следующем году все будет так же, как было последние три года».
Линейный тренд - это простейший вариант регрессии - класса алгоритмов, использующихся в машинном обучении для предсказания численных значений. Суть регрессии в разложении или, как еще говорят, декомпозиции, измеримой числовой характеристики (например, продаж) на базовые составляющие.
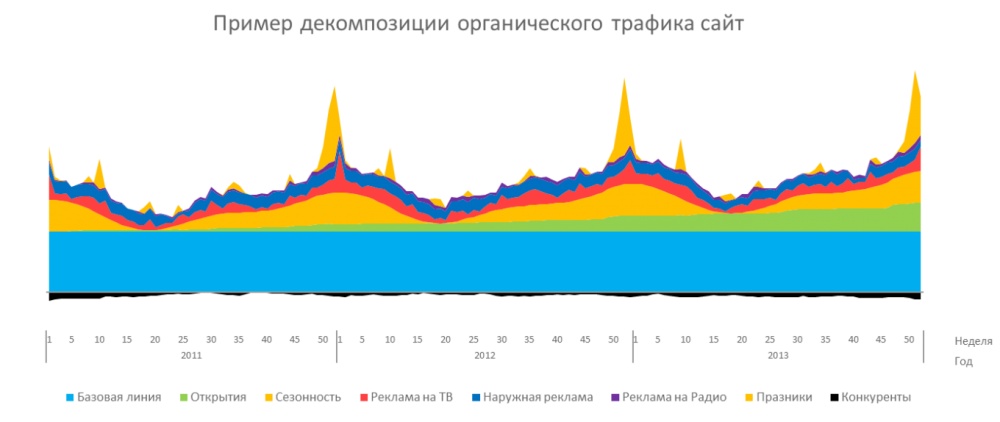
Так же, как модель самолета состоит из набора базовых деталей - крыла, двигателя, шасси и так далее, - регрессионная модель может состоять из дистрибуции, цены, рекламы. Усложнение процедуры прогнозирования происходит за счет добавления в регрессию новых факторов по мере роста объема доступных данных. Модели, где факторов больше одного, относятся к многофакторному регрессионному анализу.
В качестве простейших факторов для прогнозирования можно использовать предыдущие значения прогнозируемого показателя (авторегрессия) и среднее значение за несколько предыдущих периодов (скользящее среднее).
Пример такого прогноза: последние три месяца продажи росли в среднем на X, но последние три года в прогнозируемом периоде продажи были на Y больше, чем в другие месяцы, даже с учетом роста на X. Значит, в прогнозе мы ожидаем рост X+Y.
Так можно учесть сезонность целевого показателя (если она есть) и адаптировать прогноз к изменениям тренда. Так как для прогнозирования используются значения прогнозируемого показателя, такой подход лучше работает на коротких дистанциях (прогноз на один период вперед), чем на длинных (прогноз на три и больше периода). Иначе получается прогноз от прогноза, что ведет к быстрому росту ошибки прогнозирования.
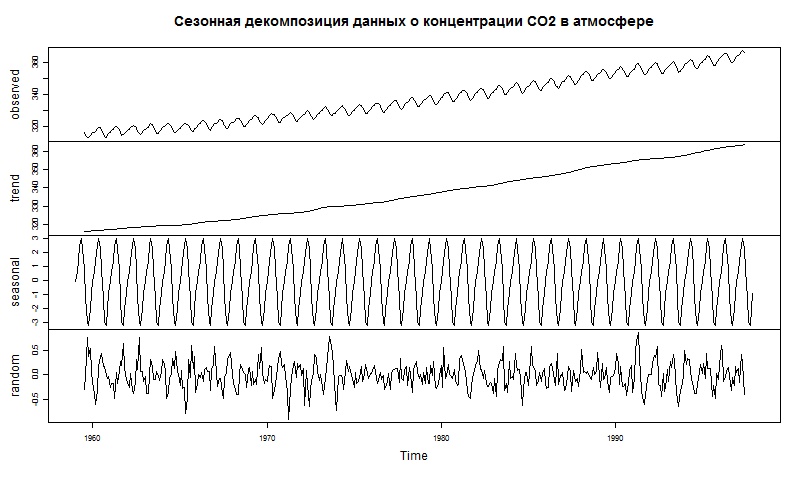
Если категория сезонна, то, накопив помесячные данные за три года, можно использовать так называемую сезонную декомпозицию - линейную регрессию, состоящую из тренда и сезонности. Дополнительная нагрузка модели факторами должна быть оправдана увеличением ее точности, и для этого в статистике есть специальные информационные критерии.
В хороших прогнозных моделях факторов обычно не больше 10% от количества доступных данных. Дальше либо факторы начинают конкурировать между собой пытаясь объяснить одно и тоже явление (проблема мультиколлинеарности), либо модель становится неустойчива, и при добавлении новых точек данных сильно меняется сила влияния отдельных факторов (проблема смещенных оценок значимости факторов).
В фармацевтической категории для одного из клиентов мы предоставляли отчет о динамике доли рынка игроков, очищенной от сезонности - это позволяет гораздо лучше понимать реальные позиции игроков на рынке и прогнозировать их развитие.
Один из способов оценить качество модели и значимость заложенных в нее факторов - разделить доступные данные на две части: обучающую и тестовую. Например, если есть понедельные данные за три года, можно построить модель на данных за 2 года и 10 месяцев, это будет обучающей выборкой, а потом сравнить прогноз от полученной модели с фактическими данными последних двух месяцев (тестовой выборкой).
Многофакторный регрессионный анализ используют во многих областях: от социологии до ядерной физики, но, когда он используется для описания бизнес-процессов, обычно используют термин эконометрическое моделирование. Преимущество использования эконометрики заключается в возможности описать степень влияния каждого отдельного фактора на целевой показатель.
Базово для построения таких моделей по-прежнему достаточно Excel, если подключить надстройку «Пакет анализа» (ее можно активировать в настройках Excel в версии для Windows, владельцам macOS потребуется Excel 2016 или сторонние надстройки). Однако Excel предоставляет ограниченную статистику по проверке качества и устойчивости моделей. Кроме того, в эконометрических моделях часто анализируются нелинейные взаимосвязи между факторами и целевым показателем.
Потенциал Excel в разработке сложных моделей сильно ограничен. Раньше такие модели разрабатывали в специализированных платных статистических программных пакетах, таких как Eviews и SPSS. В последние несколько лет основными инструментами анализа данных и построения прогнозных моделей стали языки программирования R и Python. Разработка таких моделей требует глубокого знания статистического анализа временных рядов и навыков программирования.
Когда данных становится слишком много, возникает вопрос о том, какой уровень их детализации является оптимальным для задач прогнозирования. Если, например, требуется построить прогноз динамики посетителей сайта на следующие пять лет по годам, а данные доступны в детализации по дням, то что будет более правильным: 1) суммировать исторические данные по дням и строить прогноз по годам; 2) построить прогноз по дням и прогнозировать годовые показатели как сумму прогнозных значений по дням; 3) построить прогноз по месяцам и прогнозировать годовые показатели как сумму прогнозных значений по месяцам?
Правильный ответ: выбирайте тот уровень детализации данных, на котором работают факторы, оказывающие воздействие на результат вашего прогноза. Так, если для продвижения бизнеса используется ТВ-реклама, то корректная модель должна строиться по дням или неделям - на том уровне, на котором мы видим влияние рекламы.
Чтобы определить оптимальный масштаб времени, иногда достаточно сравнить между собой графики продаж разной периодичности. Есть спорное мнение, что оценивать эффект от ТВ-рекламы на, например, посещение сайта или установку приложения надо в определенном окне (например, 15 минут) с момента выхода сообщения.
В реальности, если реклама не призывает явно совершить действие прямо сейчас, нет гарантии, что мы увидим рост целевого показателя в момент выхода рекламы. Однако реклама может увеличить вероятность того, что люди, ее увидевшие, совершат заложенное в сообщении действие, и по закону больших чисел с накоплением статистики эффект от рекламы должен становится более очевидным.
Необходимо контролировать статистическую значимость показателей на выбранном уровне детализации. Если вы - автодилер и продаете от трех до пяти машин определенной модели в день, не надо пытаться прогнозировать продажи авто по дням и рассчитывать на точность прогноза ±10%.
Как известно аналитикам, занимающимся социологическими опросами, предельная ошибка выборки прямо пропорциональна разбросу значений вокруг среднего и обратно пропорциональна корню из числа наблюдаемых значений. На практике это означает, что, чтобы получить статистически значимый результат опроса, вам надо опросить не менее 300?400 человек в каждой волне исследования. На тот же критерий можно ориентироваться и в анализе временных рядов.
С другой стороны, если анализировать динамику посетителей сайта по месяцам, кварталам или годам, будет невозможно изолировать индивидуальный эффект отдельных факторов. Например, на эффект рекламы может наложиться сезонность.
Наиболее сложные задачи прогнозирования - те, где количество доступных точек данных измеряется десятками тысяч, а количество факторов, которые могут потенциально оказать влияние - сотнями. Если нет возможность снизить размерность задачи и свести ее к регрессии, решение таких задач может потребовать привлечение одного или нескольких ученых по данным и использование таких методов машинного обучения, как, например, градиентный бустинг и нейронные сети.
Градиентный бустинг - это тестирование качества нескольких разных алгоритмов на тестовой выборке, чтобы на выходе получить «коктейль» из разных моделей, который работает лучше, чем каждая модель в отдельности.
Принцип работы нейронных сетей заключается в том, что функциональный вид модели определяется не исследователем, а рассчитывается автоматически в процессе обучения. Исследователь задает только предельную сложность модели. Сама модель при этом остается для исследования черным ящиком.
Оба подхода - градиентный бустинг и нейронные сети - хорошо зарекомендовали себя в соревнованиях по анализу данных, но обладают существенным недостатком. Они не позволяют в явном виде анализировать влияние отдельных факторов на результат прогноза. Кроме того, обучение таких моделей может потребовать значительных вычислительных мощностей, поэтому быстро изменить модель с учетом новой вводной получится далеко не всегда.
Вне зависимости от того, каким способом строится прогноз, его качество будет в первую очередь зависеть от объема и качества доступных данных.