Открыт код СУБД MapD Core, использующей GPU для ускорения обработки данных
Компания MapD Technologies объявила об открытии исходных текстов СУБД MapD Core, обеспечивающей создание хранилища в оперативной памяти (IMDB - in-memory database), ориентированного на столбцы (column-oriented). СУБД поддерживает SQL и оптимизирована для решения задач по анализу и визуализации данных. Код написан на языках C++ и Go, и распространяется под лицензией Apache 2.0.
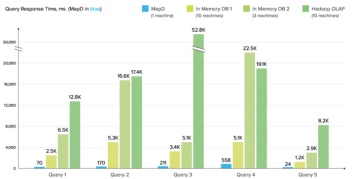
Особенностью MapD Core является задействование GPU (поддерживается NVIDIA CUDA) для ускорения анализа данных. Отмечается, что обработка данных на стороне GPU позволяет за миллисекунды выполнять запросы, охватывающие миллиарды строк, что на порядок быстрее, чем можно добиться от самых быстрых решений на основе CPU. Например, на системе с несколькими современными видеокартами можно добиться пропускной способности при работе с видеопамятью на уровне 6 TB/sec, что более чем в 40 раз быстрее, чем при работе с памятью на обычном сервере.
Если размер хранимых данных сопоставим с суммарным размером видеопамяти (VRAM) всех GPU, то данные хранятся только в видеопамяти. В противном случае видеопамять всех имеющихся GPU используется как низкоуровневый кэш, в котором поддерживается набор столбцов, наиболее часто востребованный в запросах, а для обработки сложных запросов применяется комбинированная схема, в которой параллельно используются CPU и GPU. Для экономии видеопамяти данные хранятся в сжатом виде.
При этом общий размер хранилища может многократно превышать размер видеопамяти и ограничен лишь возможностями по наращиванию ОЗУ. Но подобных комбинированный подход медленнее, поэтому для достижения наивысшей производительности рекомендуется, чтобы данные вмещались в видеопамять. Для сохранения состояния БД между перезапусками поддерживается поддержание актуального архива данных на SSD-накопителях.
Запросы оформляются на обычном SQL. Поддерживается создание фильтров, группировка и агрегирование данных, сводные запросы (join). Каждый SQL-запрос компилируется с использованием JIT-компилятора в форму, пригодную для выполнения на GPU NVIDIA, а также в виде машинных инструкций для CPU. Такой подход, основанный на идее компиляции SQL в готовый к исполнению обработчик, позволяет обойтись без интерпретаторов и планировщиков запросов. При обработке данных применяется массовое распараллеливание операций, что позволяет добиться максимальной производительности без необходимости использования индексов (перебор огромным числом параллельно выполняемых потоков выполняется быстрее, чем при использовании индексов).
Для подсоединения к СУБД поддерживаются интерфейсы JDBC, ODBC, Apache Thrift, Kafka и Sqoop. MapD также предоставляет встроенный движок отрисовки, позволяющий визуализировать результаты выполнения запросов в виде PNG-изображений на стороне СУБД (для визуализации на стороне клиента потребовалось бы передача больших объемов данных по сети). В случае необходимости создания больших хранилищ или для обеспечения отказоустойчивости MapD предоставляет средства для развертывания распределенных конфигураций. При этом движок визуализации, компоненты для создании кластерных конфигураций, а также драйверы ODBC и LDAP доступны только в коммерческой редакции MapD Analytics Platform Enterprise Edition.