Доступен Luminoth, тулкит для решения задач компьютерного зрения

Как сообщает opennet.ru Представлен выпуск тулкита Luminoth 0.1, предоставляющего инструменты для использования методов компьютерного зрения. В настоящее время функциональность Luminoth ограничена поддержкой распознавания и классификации объектов на изображениях и видео, но в будущем ожидается добавление новых методов обработки и анализа. Код проекта написан на языке Python и распространяется под лицензией BSD.
Для организации работы нейронных сетей с реализациями алгоритмов выделения объектов в Luminoth используется платформа машинного обучения TensorFlow и библиотека построения сложных нейронных сетей Sonnet (работает поверх TensorFlow). Для ускорения работы нейронной сети возможно привлечение GPU или Google Cloud ML Engine. Предоставляются две модели определения объектов - Faster R-CNN и SSD (Single Shot Multibox Detector).
Модель Faster R-CNN обеспечивает более точные результаты, но SSD работает значительно быстрее и может использоваться для определения объектов в режиме реального времени, например, для анализа видео (при использовании GPU в SSD обеспечивается скорость анализа до 60 кадров в секунду, в то время как Faster R-CNN может обработать лишь 2-5 кадров в секунду). Luminoth предоставляет готовые слепки данных моделей, уже натренированные с использованием наборов данных COCO и Pascal VOC. Для дополнительного обучения поддерживается формат наборов ImageNet. В ближайшее время ожидается интеграция поддержки моделей RetinaNet и Mask R-CNN.
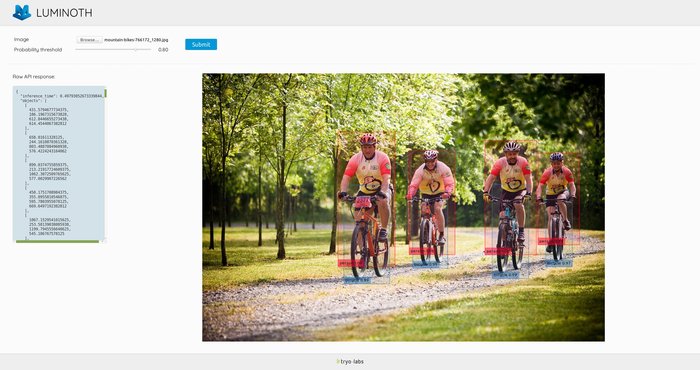
Для пользователей и разработчиков предоставляется простой интерфейс командной строки и Python API, позволяющие подключить готовые модели, при необходимости провести тренировку определения новых объектов и выполнить анализ наличия объектов (например, можно обучить систему по картинкам с динозаврами, после чего система будет сама определять есть ли на изображении динозавр, выдавать координаты выявленных объектов и при необходимости визуализировать результат).
$ lumi predict image.png Found 1 files to predict. Neither checkpoint not config specified, assuming `accurate`. Predicting image.jpg... done. { "file": "image.jpg", "objects": [ {"bbox": [294, 231, 468, 536], "label": "person", "prob": 0.9997}, {"bbox": [494, 289, 578, 439], "label": "person", "prob": 0.9971}, {"bbox": [727, 303, 800, 465], "label": "person", "prob": 0.997}, {"bbox": [555, 315, 652, 560], "label": "person", "prob": 0.9965}, {"bbox": [569, 425, 636, 600], "label": "bicycle", "prob": 0.9934}, {"bbox": [326, 410, 426, 582], "label": "bicycle", "prob": 0.9933}, {"bbox": [744, 380, 784, 482], "label": "bicycle", "prob": 0.9334}, {"bbox": [506, 360, 565, 480], "label": "bicycle", "prob": 0.8724} ] }

Последние новости раздела
-

Китайские ученые заявили о прорыве в энергетике: создана альтернатива литиевым аккумуляторам
-

Google расширяет возможности Gemini: ИИ получит доступ к истории поиска, YouTube и личным данным пользователя
-

Sid Meier’s Civilization VII станет доступна в Apple Arcade уже 5 февраля
-
Hytale официально вышла в ранний доступ: долгожданная «наследница Minecraft» доступна игрокам































































