OpenAI обучает ИИ командной работе в игре в прятки

Старая добрая игра в прятки может стать прекрасным испытанием для ботов с искусственным интеллектом (ИИ), позволяющим продемонстрировать, как они принимают решения и взаимодействуют, как друг с другом, так с различными окружающими объектами.
В своей новой статье, опубликованной исследователями из некоммерческой организации OpenAI, занимающейся исследованиями в области искусственного интеллекта и прославившейся победой над чемпионами мира в компьютерной игре Dota 2, ученые описывают как агенты, контролируемые искусственным интеллектом, обучались как изощреннее искать и прятаться друг от друга в виртуальной среде. Результаты исследования продемонстрировали, что команда из двух ботов обучается эффективнее и быстрее, чем любой отдельный агент без союзников.
Ученые использовали уже давно завоевавший свою славу метод машинного обучения с подкреплением, в котором искусственный интеллект помещается в неизвестную ему среду, имея при этом определенные способы взаимодействия с ней, а также систему наград и штрафов за тот или иной результат своих действий. Данный метод достаточно эффективен благодаря возможностям ИИ выполнять различные действия в виртуальной среде с огромной скоростью, в миллионы раз быстрее, чем может представить человек. Это позволяет методом проб и ошибок найти наиболее эффективные стратегии для решения поставленной задачи. Но у данного подхода также есть некоторые ограничения, например, создание среды и проведение многочисленных циклов обучения требует огромных вычислительных ресурсов, а сам процесс нуждается в точной системе сопоставления результатов действий ИИ с поставленной ему целью. Кроме того, приобретенные агентом таким образом навыки ограничены описанной задачей и, как только ИИ научится с нею справляться, никаких улучшений большей уже не будет.
Для обучения ИИ игре в прятки ученые использовали подход, называющийся "ненаправленное исследование" (Undirected exploration), который заключается в том, что агенты имеют полную свободу действий для развития своего понимания игрового мира и разработки выигрышных стратегий. Это похоже на подход к многоагентному обучению, который применяли исследователи из DeepMind, когда несколько систем искусственного интеллекта были обучены играть в режиме "захват флага" в игре Quake III Arena. Как и в этом случае, агенты ИИ не были заранее обучены правилам игры, но со временем они выучили базовые стратегии и даже смогли удивить исследователей нетривиальным решениями.
При игре в прятки нескольким агентам, чьей задачей было прятаться, было необходимо избегать прямой линии видимости соперников после небольшой форы во времени, пока команда ищущих агентов была обездвижена. При этом "линия видимости" в данном контексте представляет собой конус в 135 градусов перед отдельным ботом. Агенты не могли удаляться слишком далеко за пределы игровой площадки и были вынуждены перемещаться по случайно сгенерированным комнатам с возможностью использовать некоторые внешние объекты (ящики, передвижные стены, специальные пандусы), разбросанные вокруг, которые можно было использовать как для создания укрытий, так и для проникновения в них.
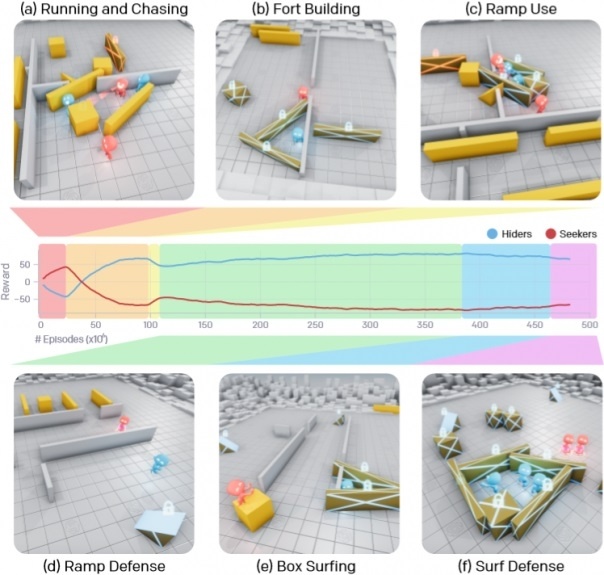
В результате долгого процесса обучения ИИ-агенты освоили шесть уникальных стратегий, каждая из которых помогала им переходить к следующему этапу игры. Вначале команды ищущих и прячущихся просто убегали и преследовали друг друга, но после примерно 25 миллионов матчей команда прячущихся научились блокировать проходы коробками и строить из них укрытия. После еще 75 миллионов матчей команда ищущих обнаружила способы использовать пандусы, чтобы проникать в эти укрытия. Спустя еще 10 миллионов раундов прячущиеся научились оттаскивать пандусы к краю игровой площадки и фиксировать их на месте, чтобы не позволить противникам использовать их.
После 388 миллионов матчей ищущие научились использовать заблокированные пандусы, чтобы подняться на принесенные к ним ящики, а затем, перемещаясь прямо на них, проникать в созданные из переносных стен укрытия противников. И, наконец, после 458 миллионов матчей прячущаяся команда сделала вывод, что нужно заблокировать вообще все объекты, а затем построить укрытие, что и привело, по всей видимости, к ее окончательной победе.
Что особенно впечатляет, так это то, что уже после 22 миллиона матчей агенты научились координировать свои действия и в дальнейшем эффективность их совместной работы только увеличивалась, например, каждый приносил свой ящик или стенку для создания укрытия и выбирал свою долю объектов для блокировки, чтобы усложнить игру противникам.
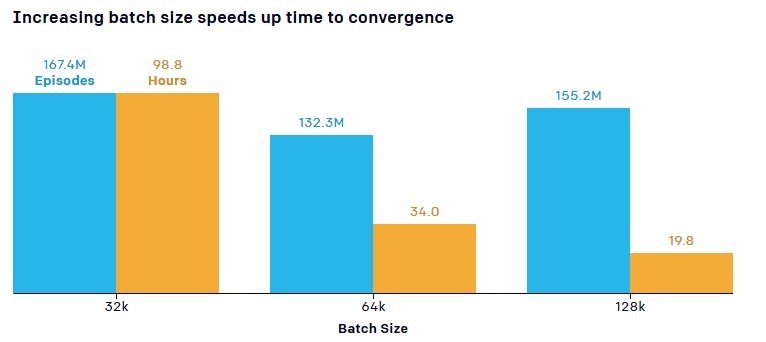
Ученые также отметили важный момент, связанный с влиянием количества тренировочных объектов (объемом пропускаемой через нейронную сеть данных - "Batch Size") на скорость обучения. Для модели по умолчанию требовалось 132,3 миллиона матчей в течение 34 часов обучения, чтобы достичь фазы на которой прячущаяся команда научилась блокировать пандусы, в то время как больший больший объем данных привел к заметному сокращению времени обучения. Например, увеличение количества параметров (части данных, полученных в течении всего процесса обучения) с 0,5 млн до 5,8 млн повысило эффективность выборки в 2,2 раза, а увеличение размера входных данных в с 64 Кбайт до 128 Кбайт сократило время обучения почти в полтора раза.
В конце своей работы исследователи решили проверить, насколько обучение в игре может помочь агентам справляться со схожими задачами вне игры. Всего тестов было пять: осознание количества объектов (понимание, что объект продолжает существовать, даже если он находится вне видимости и не используется); "заблокировать и вернуться" - способность запомнить свое изначальное положение и вернуться к нему после выполнения какой-либо дополнительной задачи; "последовательная блокировка" - 4 ящика случайным образом были расположены в трех комнатах без дверей, но с пандусами для попадания внутрь, агентам необходимо было найти и заблокировать их все; размещение ящиков на заранее заданных площадках; создание укрытия вокруг объекта в виде цилиндра.
В результате в трех из пяти заданий боты, прошедшие предварительную подготовку в игре, обучались быстрее и показали лучший результат, чем ИИ, который обучался решению задач с нуля. Они немного лучше справились с выполнением задачи и возвратом на начальную позицию, последовательной блокировкой ящиков в закрытых комнатах и с размещением ящиков на заданных площадках, но показали немного более слабый результат при осознании количества объектов и созданию укрытия вокруг другого объекта.
Исследователи объясняют неоднозначный результаты в том, как ИИ получает и запоминает определенные навыки. "Мы думаем, что задачи, в которых предварительная подготовка в игре показала лучший результат, связаны с повторным использованием ранее изученных навыков привычным образом, в то время как для выполнения оставшихся задач лучше, чем обученный с нуля ИИ, потребуется использование их другим образом, что намного сложнее", - пишут соавторы работы. "Этот результат подчеркивает необходимость разработки методов эффективного повторного использования навыков полученных в результате обучения при переносе их из одной среды в другую".
Проделанная работа действительно впечатляют, так как перспектива использования данного метода обучения лежит далеко за пределом каких-либо игр. Исследователи утверждают, что их работа является значительным шагом к созданию ИИ с "физически обоснованным" и "человеческим" поведением, который сможет диагностировать заболевания, предсказывать структуры сложных белковых молекул и анализировать компьютерную томографию.
На видео ниже вы можете наглядно увидеть, как проходил весь процесс обучения, как ИИ учился командной работе, а его стратегии становились все более хитрыми и сложными.



Последние новости раздела
-

Google расширяет возможности Gemini: ИИ получит доступ к истории поиска, YouTube и личным данным пользователя
-

Sid Meier’s Civilization VII станет доступна в Apple Arcade уже 5 февраля
-
Hytale официально вышла в ранний доступ: долгожданная «наследница Minecraft» доступна игрокам
-

Тайвань выдал ордер на арест основателя OnePlus Пита Лау по делу о незаконном найме инженеров