Искусственный интеллект DeepMind научился делать умозаключения

Команда ИИ-специалистов из Британии и США исследовала, может ли искусственный интеллект обобщить свой опыт, полученный в ходе взаимодействий с объектами в двух- и трехмерной среде.
Специалисты DeepMind, Стэнфордского университета и Университетского колледжа Лондона исследовали возможность интеллектуальных агентов применять полученные знания для выполнения следующих задач, лишь косвенно связанных с предыдущей. Результаты показывают, что в среде, сгенерированной игровым движком Unity, агенты под управлением ИИ корректно использовали "композиционную природу" языка, чтобы интерпретировать инструкции, которые они никогда ранее не встречали, пишет VentureBeat.
"ИИ, обучавшиеся в идеализированных или усеченных ситуациях, могут быть лишены композиционного или систематического понимания своего опыта. Это знание возникает у них, когда они, как и учащиеся люди, получают доступ к разнообразным примерам и многосторонним наблюдениям, - говорится в статье. - Следовательно, во время обучения агент учится не только следовать инструкциям, но и узнает, как образованы текстовые символы и как комбинация этих слов воздействует на то, что должны делать агенты".
Ученые исследовали вопрос, до какой степени они могли бы наделить модель ИИ "систематичностью" - свойством сознания, с помощью которого способность обдумывать мысль воздействует на способность размышлять о чем-то семантически родственном. Например, систематичность позволяет человеку, понявшему фразу "Джон любит Мэри", понять также и "Мэри любит Джона".
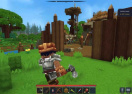
В серии экспериментов ИИ, наблюдающий за миром от первого лица, получил задачу выполнять инструкции вроде "найти зубную щетку" и "поднять вертолет". В результате агент справился с 26 действиями, а после обучения он смог выполнить задачу всего за шесть действий. В частности, он понял значение приказа "подними" достаточно полно, чтобы выполнить это действие с объектом, которого ранее не видел.
Любопытно, что агенты, прошедшие обучение в трехмерных мирах, показывали лучшие результаты генерализации, чем те, которых тренировали в 2D.
Три фактора ученые сочли наиболее важными во всех тестах: число слов и объектов, с которыми взаимодействовал агент; вид от первого лица; разнообразие входящих сигналов, доступных агенту.