Нейросеть освоила видеоигру по языковому гайду

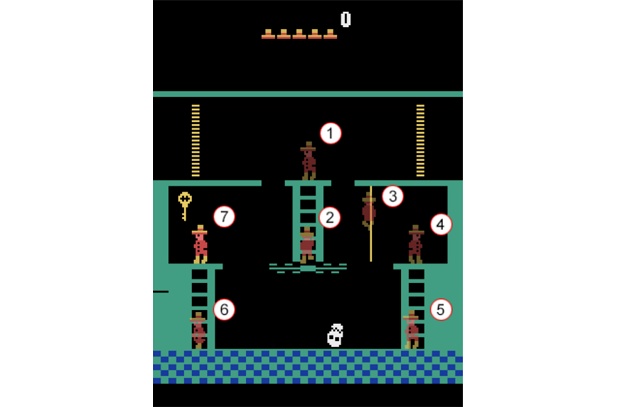
В большинстве случаев при обучении искусственных нейросетей прохождению видеоигр используются алгоритмы с подкреплением - этот метод предполагает получение компьютером внешней обратной связи о своих действиях, например в виде зарабатывания очков. В процессе тренировок система совершает произвольные действия до получения вознаграждения, после чего стремится повторить «выгодный» шаблон. Авторы новой работы при обучении нейросети применили альтернативный подход, позволивший ей освоить одну из сложнейших видеоигр для приставки Atari 2600 - «Месть Монтесумы» (Montezuma's Revenge). Из-за специфики геймплея она не впервые участвует в экспериментах с искусственным интеллектом: в этой игре редко встречаются положительные и доступные для оценки стимулы, такие как ключ для отпирания двери.
Чтобы упростить тренировку нейросети при прохождении игры с недостатком источников подкрепления, на первом этапе студенты обучили систему распознаванию команд на естественном языке, при этом фразы сопровождались скриншотом целевого действия игрового персонажа. Затем они передали алгоритму набор команд для прохождения каждой локации и позволили самостоятельно практиковаться. В рамках демонстрации авторы описали прохождение нейросетью комнаты с последовательностью команд типа «поднимись по лестнице» без доступа к данным о прошлых этапах обучения - это имитировало ситуацию первичного ознакомления с комнатой. Результаты показали, что искусственный интеллект верно интерпретировал команды и даже игнорировал некоторые из них при условии, что существует более оптимальная стратегия прохождения.
Эффективность предложенного подхода студенты оценили с помощью платформы для проектирования и сравнения алгоритмов обучения с подкреплением OpenAI Gym. Согласно сопоставлению, представленная нейросеть за время прохождения Montezuma's Revenge набрала 3500 очков, тогда как показатель ближайшего конкурента составил 2500 очков. Тем не менее, максимальное значение по-прежнему остается за алгоритмом Google DeepMind - 6600 очков, - хотя обучение последнего потребовало двое больше времени. В последующем авторы статьи намерены сократить количество инструкций на естественном языке, необходимых для освоения нейросетями видеоигр, с тем чтобы сделать их более независимыми.
Подробности работы представлены на сервере препринтов arXiv.org.
Ранее международная группа исследователей представила компьютерную программу, которая самостоятельно научилась сложным тактикам игры в StarCraft. Так, система освоила тактику «Ударил-убежал», атаку прикрывающим огнем и сосредоточенный огонь по отдельным целям малыми группами. По мнению исследователей, алгоритм оптимально подходит для взаимодействия и тренировки с несколькими агентами.
Последние новости раздела
-

Китайские ученые заявили о прорыве в энергетике: создана альтернатива литиевым аккумуляторам
-

Google расширяет возможности Gemini: ИИ получит доступ к истории поиска, YouTube и личным данным пользователя
-

Sid Meier’s Civilization VII станет доступна в Apple Arcade уже 5 февраля
-
Hytale официально вышла в ранний доступ: долгожданная «наследница Minecraft» доступна игрокам