Microsoft разработала модель, которая имитирует голос человека на основе трехсекундной записи

Группа исследователей из Microsoft презентовала новую модель для синтеза речи на основе нейросетевых алгоритмов. Она получила название VALL-E.
Главная фишка VALL-E - копирование голоса человека. Чтобы обучиться копировать голос, нейросети требуется его запись продолжительностью всего в три секунды. Помимо сохранения вокального тембра и эмоций говорящего, VALL-E может имитировать «акустическое окружение» - например, будто речь звучит как при телефонном звонке. Технология основана на алгоритме EnCodec и обучена на 60 000 часах англоязычной речи от более чем 7000 носителей.
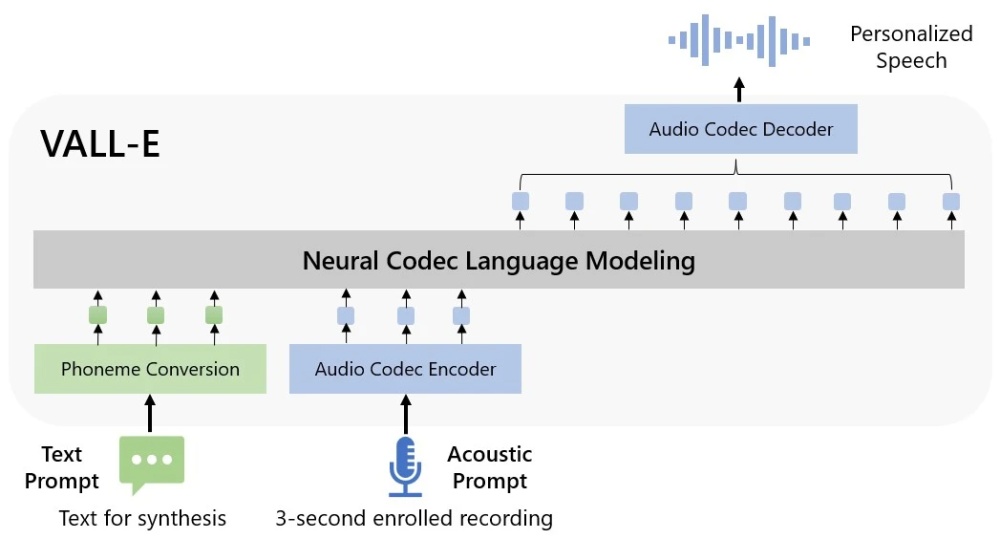
На специальном сайте Microsoft предоставляет несколько десятков примеров работы VALL-E. В колонке Speaker Prompt представлена оригинальная трехсекундная запись голоса, в колонке Ground Truth - полное прочтение заданной фразы для сравнения. Колонка Baseline показывает результат работы обычной технологии синтеза речи. Наконец, в колонке VALL-E представлен результат работы новой технологии Microsoft.
Исследователи уточняют, что понимают риски технологии - злоумышленники могут воспользоваться ей, чтобы выдать себя за другого человека. Поэтому специалисты предлагают создать алгоритм, который определяет, что аудиозапись создана при помощи VALL-E.
Последние новости раздела
-

Copilot может получить отдельную панель в «Проводнике» Windows 11
-

Larian прояснила позицию по ИИ: сценарии и концепт-арты Divinity создаются без нейросетей
-

На CES 2026 представили водонагреватель Superheat H1 с функцией майнинга биткоина
-

IKEA представила на CES 2026 ультрабюджетные Bluetooth-колонки Kallsup, которые можно объединять в сеть до 100 устройств